前回Apach Airflowの概要について調べました。(こちら)
ジョブの実行やエラーだった時にメール送信やリトライする機能を実現しようとした時に、ジョブ管理システムの導入や導入しているシステムを利用することが一般的だと思います。ジョブ管理システムの有名なところとしては、JP1やSystemwalkerなどは聞いたことがある方もいるのではないでしょうか。
JP1やSystemwalkerなどの大規模基幹システムでは運用監視などを前提としているため、スモールスタートしたい場合にはどうしてもオーバースペックになってしまいます。
Airflowはそれらジョブ管理システムの代替になるわけではないのですが、データ基盤(ETL/ELT)やAI/MLパイプラインとして活用する機能を活用することで、スモールにシステム構成を構築できることができます。
今回は実際にジョブ管理システムとして利用することを想定した場合の利用方法について調査した内容の備忘録となります。
Dag間連携を必要とするケース
Dagには複数のタスクを定義して実行の順番を制御することができますが、Dag自体を分けてDagの実行順序を制御するDag間連携の方法もあります。
どのような設計思想でDag間連携を採用するか、
システム責務(担当領域)が異なるケース
部門が違う or 処理担当チームが違う場合、1つのDagにすると運用負荷や権限設計が複雑になるためDagを分割 → 依存連携するようなケースになります。
DAG_A:データ収集
DAG_B:データ加工・集約
DAG_C:分析結果をBIへ連携
長い処理を段階別に独立管理したいケース
大規模バッチ・ETLでは、途中で失敗したときの再実行範囲を細かく制御したいため、処理を分割する。
→ Dag失敗時の再実行単位として分けるのが合理的と判断するケースになります。
異なるスケジュールベースの処理を依存制御したい場合
常に時間ベースではなく、イベントベースで動きたい場合に有効。
| DAG | スケジュール | 条件 |
|---|---|---|
| DAG_A(入力データ収集) | 毎日 0:00 | 自律スケジュール |
| DAG_B(集計) | 実行条件:DAG_Aが成功したら動く | スケジュール不要 |
処理内容がモジュール化され、複数Dagから再利用したい場合
例えば、
DAG_X:日次処理
DAG_Y:月次処理
のように、再利用性・保守性の観点で DAG を分割し、トリガーで繋ぐのが合理的なケース。
検証/リリース境界が異なる場合
DAG_A の変更=DAG_B には関係ない場合、
ワークロード分割することで:
• CI/CD容易化
• ロールバック容易化
• 可観測性(ログ・監査)の明確化
につながるようなケース。
外部システム連携が挟まる場合
ステップ間に手動承認 or 外部依頼フェーズがある場合、DAGを分けると運用制御が柔軟になるようなケース。
DAG1 → DBロード
↓ 完了通知
DAG2 → 外部API呼び出し or BI更新
Dagが終わったら次のDagを実行する方法
今回は2つのDagを作成します。
親のDagを作成
from airflow.sdk import dag, task
from airflow.providers.standard.operators.trigger_dagrun import TriggerDagRunOperator
import pendulum
@dag(
dag_id="parent_dag",
start_date=pendulum.now(),
schedule=None,
catchup=False, # 過去分(スケジュール分)の追いかけ実行有無。デフォルト:True
tags=["example", "dag_to_dag"]
)
def dag_parent():
@task
def prepare():
return "start child"
trigger = TriggerDagRunOperator(
task_id="trigger_child",
trigger_dag_id="child_dag", # ← 実行対象の別のDAG
wait_for_completion=True, # ← 子DAGの実行が終わるまで親DAGの次タスクへ進まない(同期実行)。デフォルト: False
poke_interval=10, # デフォルトは60秒
)
prepare() >> trigger
dag_parent()
ポイントはTriggerDagRunOperatorというOperatorを使いあるDagから別のDagを実行することができます。
| パラメータ | 意味 |
|---|---|
| trigger_dag_id | 実行したいDAGの dag_id |
| wait_for_completion=True | 子DAGが終わるまで待つ(同期実行) |
| wait_for_completion=False | 起動だけして次に進む(非同期) |
子のDagを作成
from airflow.sdk import dag, task
from airflow.providers.standard.operators.trigger_dagrun import TriggerDagRunOperator
import pendulum
@dag(
dag_id="child_dag",
start_date=pendulum.now(),
schedule=None,
catchup=False, # 過去分(スケジュール分)の追いかけ実行有無
tags=["example", "dag_to_dag"]
)
def dag_child():
@task
def run_child():
return "Child DAG executed!"
run_child()
dag_child()
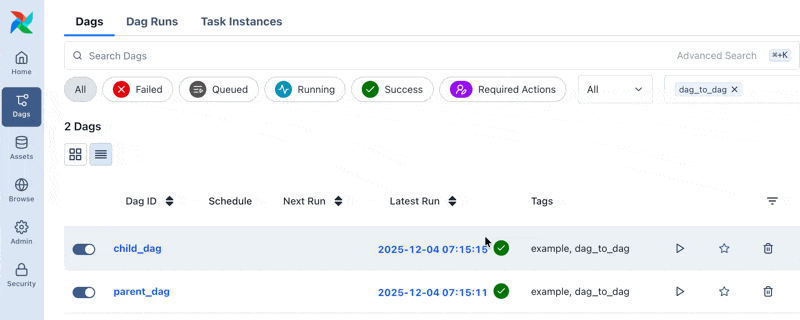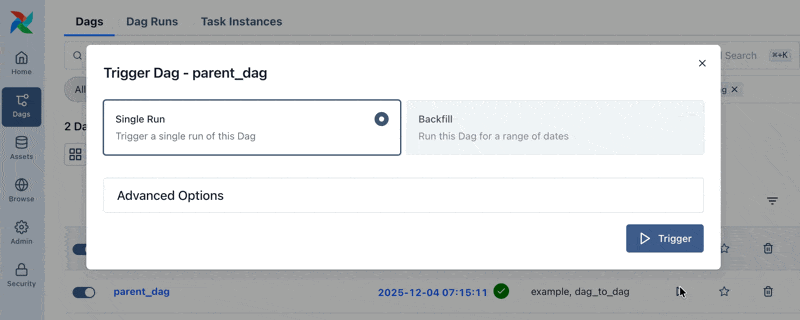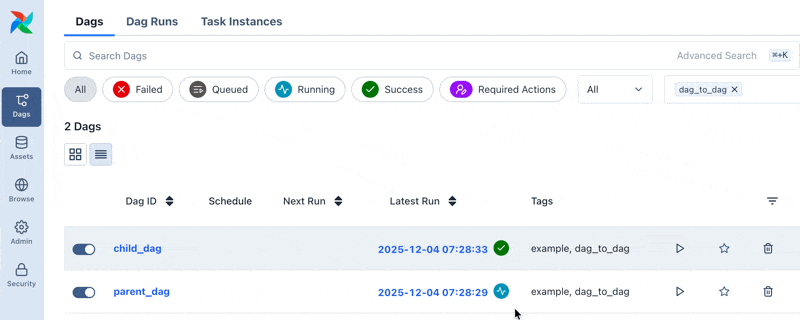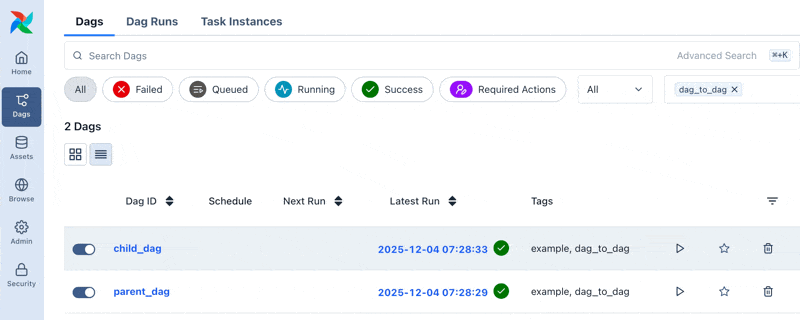
airflowの管理画面で起動してみる
親のDagparent_dagを実行すると子のDagchild_dagが自動で実行されます。
よくある異常終了時のDag定義について
ジョブを管理する際に指定したジョブが失敗したら、失敗を通知したいシーンはよくあるケースですが、Aireflowでも同様のことが実現できます。
そもそも「失敗」として扱われる状態について確認しておきたいと思いますが、 Airflowでは以下の状態を例外などが失敗として扱われる状態となります。
- shell、Javaのexit code ≠0
- Pythonの例外送出
- Sensor が timeoutする
- 明示的に AirfowFailException を投げる
shellやアプリケーションではどのような「失敗」のケースがあるか想定してみると、
APIやDBなどへの通信エラー、取得したファイルの形式違い、想定外の値による不整合、データ無しなどがよくあるパターンだったりすると思います。
このようなエラーが発生した場合、業務要件や設計次第ではありますが、一般的には以下のような対応を取ることが考えられるでしょう。
一時的な障害 → リトライする
- 発生事象の状態
- DB一時ロックへの対応
- 外部APIの瞬断対応
from airflow.sdk import dag, task
from datetime import timedelta
import pendulum
@dag(
start_date=pendulum.datetime(2025, 1, 1),
schedule=None,
catchup=False,
default_args={
"retries": 3, # DAG全体のリトライ指定
"retry_delay": timedelta(minutes=2),
},
)
def retry_task_level():
@task(
retries=2,
retry_delay=timedelta(minutes=10),
)
def unstable_task():
raise Exception("Temporary failure")
@task
def stable_task():
print("Always OK")
unstable_task() >> stable_task()
retry_task_level()
- Dag全体は
default_argsで定義。 - 特定のタスクでのリトライも定義可能。Dagとタスクの両方の指定がある場合は、タスクが優先される。
入力データ不正 → 失敗させて通知する
- 発生事象の状態
- CSVフォーマット不正
- 必須カラム欠落
import json
import urllib.request
def notify_slack_on_failure(context):
webhook_url = context["var"].get("SLACK_WEBHOOK_URL")
dag_id = context["dag"].dag_id
task_id = context["task_instance"].task_id
execution_date = context["logical_date"]
log_url = context["task_instance"].log_url
exception = context.get("exception")
message = {
"text": (
":x: *Airflow Task Failed*\n"
f"*DAG*: {dag_id}\n"
f"*Task*: {task_id}\n"
f"*Execution*: {execution_date}\n"
f"*Reason*: {exception}\n"
f"<{log_url}|View Log>"
)
}
req = urllib.request.Request(
webhook_url,
data=json.dumps(message).encode("utf-8"),
headers={"Content-Type": "application/json"},
)
urllib.request.urlopen(req)
context["var"].get("SLACK_WEBHOOK_URL")はAirflowのVariablesで定義することでDag全体で共有することが可能となります(メニュー:Admin > Variables)。context["task_instance"].log_urlでログURLをセットしています。ここからAirflowの該当ログへ直行できるようにします。
外部依存失敗 → 待機 or 分岐させる
- 発生事象の状態
- S3ファイル未到達
- 下流システムメンテ中
ローカルファイル監視
from airflow.sdk import dag, task
from airflow.providers.standard.sensors.filesystem import FileSensor
import pendulum
@dag(
dag_id="file_wait_pipeline",
start_date=pendulum.datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["sensor", "file"],
)
def file_wait_pipeline():
wait_for_file = FileSensor(
task_id="wait_for_input_file",
filepath="/opt/airflow/data/input.csv",
poke_interval=60, # 60秒ごとに確認
timeout=60 * 30, # 30分待って来なければ失敗
mode="reschedule", # Workerを占有しない(重要)
)
@task
def process():
print("File detected. Processing...")
wait_for_file >> process()
file_wait_pipeline()
FileSensorクラスを利用しています。
S3のファイル到着を待つ定義
from airflow.providers.amazon.aws.sensors.s3 import S3KeySensor
wait_for_s3 = S3KeySensor(
task_id="wait_for_s3_file",
bucket_name="my-bucket",
bucket_key="incoming/data.csv",
poke_interval=120,
timeout=60 * 60,
mode="reschedule",
)
S3KeySensorクラスを利用してS3のファイルを指定時間の待機しています。
状態により分岐させる
対象データの有無やメンテナンス判定など条件により分岐させるパターン
from airflow.operators.branch import BranchPythonOperator
from airflow.sdk import dag, task
import pendulum
def check_external_status(**context):
# 疑似的な外部状態
system_available = False
# 条件でcallするtaskを分岐
if system_available:
return "do_process"
else:
return "skip_process"
@dag(
dag_id="external_status_branch",
start_date=pendulum.datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["branch"],
)
def external_status_branch():
branch = BranchPythonOperator(
task_id="check_status",
python_callable=check_external_status,
)
@task
def do_process():
print("External system OK. Processing.")
@task
def skip_process():
print("External system NG. Skip processing.")
# 分岐させるtaskを配列で指定
branch >> [do_process(), skip_process()]
external_status_branch()
BranchPythonOperatorクラスを利用して分岐させる。python_callableに分岐条件となる関数を指定します。
業務的にNG → 即時停止させる
- 発生事象の状態
- マスタ不整合
- 業務データが論理的に破綻
from airflow.exceptions import AirflowFailException
@task
def critical_check(data):
if data["amount"] < 0:
raise AirflowFailException("Negative amount detected")
AirflowFailExceptionはAirflowのタスクを失敗(failed)にするクラスで、もしretryがあっても即時にfailedになります。
ポイント
発生するエラー時にリトライ、失敗通知、スキップ を軸にどのようなエラーについてどのような選択を行うのか基準を設けてシステム内で統一感を持つことが大事だと思います。
まとめ
今回はDagからDagを実行するケースを調査してみました。
1つのDagでどこまでまとめて定義するか、Dagを分割するかは基準を設け設計することでシステムの統一感を持たせるようにする方が望ましいでしょう。
TriggerDagRunOperatorに次に実行したいDagを指定することでDagからDagを実行することを確認しました。
次は、Apache Airflow:構築環境について 紹介したいと思います。





コメント