前々から分散データ処理やデータプラットフォームについて興味がありFluentdなどの書籍は読んだりしていたのですが、今回は自身の業務でもジョブ管理システムについて調べる必要があったりしたので、今回はワークフロー管理ツールである「Apache Airflow」についての内容をまとめてみました。
Apache Airflowとは?💡
Apache Aireflowは、
ワークフローをプログラムで作成、スケジュール、監視するためにコミュニティによって作成されたプラットフォーム
となります。
なので、ジョブの実行の定義をPythonで作成したり、管理用画面が用意されていたりするプラットフォームになります。
Apache Airflow誕生の背景
2014年にAirbnbの元FacebookのエンジニアMaxime Beaucheminによって開発され、その当時、
- ジョブの依存関係が見えない
- 運用が属人化
- ログが散財し追跡困難
- 変更・追跡が容易でない
という課題を抱えていたとのことです。
Airbnbは、上記問題に対して「データパイプラインをコードで定義し、視覚的・運用的に制御可能にする」という思想でAirflowを開発したようです。
Apache Airflowの特徴
1.スケーラブル
モジュール型アーキテクチャを採用しており、メッセージキューを使用して任意の数のワーカーをオーケストレーションします。Airflow は無限に拡張可能。
2.動的管理
パイプラインはPythonで定義されており、動的なパイプライン生成が可能です。これにより、パイプラインを動的にインスタンス化するコードを記述できる。
3.伸長性
独自の演算子を簡単に定義し、環境に適した抽象化レベルに合わせてライブラリを拡張できる。
4.エレガント
Apache Airflow® パイプラインは、シンプルで明示的な設計。強力な Jinja テンプレートエンジンを使用したパラメータ化は、そのコア部分に組み込まれている。
支持される理由
Aireflowは業界標準のワークフローエンジンとされ、多くのクラウド・企業・OSSプロジェクトで採用されていますが、支持される理由としては以下があげられます。
- 柔軟性と拡張性
- Pythonで定義するので基本的にcronなどのツールより柔軟に条件分岐や動的な処理を管理することができる。
- 可視化と運用性の高さ
- DAGの構成、各タスクのログ、失敗タイミングが全てGUIで追える。
- メール・Slack通知、Webhooksも設定可能。
- 豊富なOperatorとプラグイン群
- BashOperator, PythonOperator, EmailOperator, KubernetesPodOperator, S3Operator, MySqlOperator… など豊富。
- 自作オペレーターも作成して追加することができる。
- AWS、Azure、GCPとの統合プラグインも豊富
- 大規模運用への耐性と分散処理
- Executer(Celery、KubernetesExecutor)を使えば大規模分散環境にも対応可能
- ベンダーによるマネージサポートが増加
- GCP→Cloud Composer
- AWS→MWAA(Managed Workflows for Apache Aireflow)
- Azure → Data Factory 統合 Managed Airflow
Aireflowが開発され、ここまで支持されている理由は単純に「ジョブをスケジュールできる」からではなく、コードベースで再現性のあるワークフローが管理できることで、属人化を排除したり拡張性・運用性のバランスがよいためとなります。
今後はLLMを活用できるエンジニアやデータエンジニア、インフラエンジニアなどが活躍するためにも、Airflowというデータプラットフォームの理解、活用できるようにすることが求められていくと思います。
Aireflowの要素
Dag(Directed Acyclic Graph)とは
Apache Airflow の根幹を成す概念の一つがDag(Directed Acyclic Graph)になります。私は、Airflowを調べるまでDagというものが何なのかわかりませんでした。。
Airflowを理解する上で「Dag」を理解することは重要になるので、用語を分解して理解していきたいと思います。
| 用語 | 意味 |
| Directed : 有向 | 向きが有る。 taskA→taskBというような流れ。 |
| Acyclic : 非巡回 | ループしない。 taskA→taskB→taskC→taskAのような循環禁止。 |
| Graph : グラフ | ノード(タスク)とエッジで構成される構造体。 |
Dagのイメージ
Dagの属性
Airflowの動作はDagが担っており、ワークフローの実行に必要なすべてをカプセル化したモデルになり、次の様な属性を含むものです。
Schedule - スケジュール
ワークフローを実行するタイミング。
Tasks - タスク
タスクはWorker上で実行される個別の作業単位。
Task Dependencies - タスクの依存関係
タスクが実行される順番と条件。
コールバック - Callbacks
ワークフロー全体が完了したときに実行されるアクション。
追加パラメータ - Additional Parameters
その他多くの操作詳細。
Dagのサンプルコード
Dagの基本が確認できるサンプルコードが以下になります。
from datetime import datetime
from airflow.sdk import DAG, task
from airflow.providers.standard.operators.bash import BashOperator
# A Dag represents a workflow, a collection of tasks
with DAG(dag_id="demo", start_date=datetime(2025, 11, 1), schedule="0 0 * * *") as dag:
# Tasks are represented as operators
hello = BashOperator(task_id="hello", bash_command="echo hello")
@task()
def airflow():
print("airflow")
# Set dependencies between tasks
hello >> airflow()
dag_id="demo"がDagの名前を指定する部分になります。start_date=datetime(2025, 11, 1), schedule="0 0 * * *"が2025年11月1日の0時0分になります。"0 0 * * *"の部分は前の値から「時」「日」「月」「年」「週」の設定となります。
- helloは
BashOperatorを使用してshell scriptを実行し、airflowは@taskデコレータを使用して定義しています。BashOperatorの他には以下のようなオペレータが利用可能です。PythonOperator- Python関数をコールEmailOperator- Eメールを送信SimpleHttpOperatro- HTTPリクエストを送信Sensor- 特定の時間、ファイル、データベース行、S3 キーなどを待機。
>>は2つのタスク間の依存関係を定義して、実行順序を制御するものになります。>>は想像どおり、op1 >> op2のときに op1が終わってからop2を実行する指定方法。op1.set_downstream(op2)という指定も同じ意味になる。<<はop2 << op1とop1 が完了してから op2 を実行する。op2.set_upstream(op1)も同じ意味になる。op3.set_upstream([op1, op2])はop1,op2が完了したらop3を実行するという意味になります。
op1 >> op3 op2 >> op3
Airflowを動かしてみる(ローカルPC by Docker)
Airflowの公式がdocker composeを提供しているのでdocker composeでサクッと起動していきます。
Version: 3.1.3 が最新の安定版となるので、この手順を元に実施していきます。
docker composeを取得する。
Airflowをデプロイするためのdocker-compose.yamlを取得します。
curl -LfO 'https://airflow.apache.org/docs/apache-airflow/3.1.3/docker-compose.yaml'
導入のための初期設定
ディレクトリ作成と.envの作成
mkdir -p ./dags ./logs ./plugins ./config echo -e "AIRFLOW_UID=$(id -u)" > .env
docker composeの起動
docker compose run airflow-cli airflow config list # airflow-cli:docker-compose.yaml 内で定義されたサービス名。Airflow CLI 専用の軽量コンテナ # airflow config list:Airflow の設定(airflow.cfg)をリスト表示する CLI コマンド
データベースの初期化
docker compose up airflow-init
初期化が完了すると、ファイル、フォルダー、プラグインに関連する出力が表示され、最後に次のようなメッセージが表示されます。
airflow-init-1 exited with code 0全てのサービスを実行させる
docker compose up
docker-compose.yaml で定義されているサービスは以下になります。ダウンロードされるdocker-compose.yamlのコメント部分を除外した内容についても記載します。
airflow-scheduler
すべてのtaskとDagを監視し、依存関係が完了するとタスクインスタンスをトリガーします。
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8974/health"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfullyairflow-dag-processor
DagプロセッサはDagファイルを解析するためのサービスです。
airflow-dag-processor:
<<: *airflow-common
command: dag-processor
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type DagProcessorJob --hostname "$${HOSTNAME}"']
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfullydocker compose up を行い出力内容に以下のような出力を定期的に行われることが確認できます。
:
:
airflow-dag-processor-1 | 2025-11-23T09:39:29.685973Z [info ] Not time to refresh bundle example_dags [airflow.dag_processing.manager.DagFileProcessorManager] loc=manager.py:550
airflow-dag-processor-1 | 2025-11-23T09:39:30.697466Z [info ]
airflow-dag-processor-1 | ================================================================================
airflow-dag-processor-1 | DAG File Processing Stats
airflow-dag-processor-1 |
airflow-dag-processor-1 | Bundle File Path PID Current Duration # DAGs # Errors Last Duration Last Run At
airflow-dag-processor-1 | ------------ ---------------------------------------------------------- ----- ------------------ -------- ---------- --------------- -------------------
airflow-dag-processor-1 | example_dags tutorial_objectstorage.py 1 0 1.09s 2025-11-23T09:39:08
airflow-dag-processor-1 | example_dags example_setup_teardown_taskflow.py 1 0 1.08s 2025-11-23T09:39:15
airflow-dag-processor-1 | example_dags example_dag_decorator.py 1 0 1.07s 2025-11-23T09:39:13
:
:airflow-api-server
api server は http://localhost:8080で利用できます。
airflow-apiserver:
<<: *airflow-common
command: api-server
ports:
- "8080:8080"
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/api/v2/version"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfullyairflow-worker
スケジューラによって指定されたタスクを実行する役割を担います。
airflow-worker:
<<: *airflow-common
command: celery worker
healthcheck:
test:
- "CMD-SHELL"
- 'celery --app airflow.providers.celery.executors.celery_executor.app inspect ping -d "celery@$${HOSTNAME}" || celery --app airflow.executors.celery_executor.app inspect ping -d "celery@$${HOSTNAME}"'
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
environment:
<<: *airflow-common-env
DUMB_INIT_SETSID: "0"
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-apiserver:
condition: service_healthy
airflow-init:
condition: service_completed_successfullyairflow-triggerer
Airflow 2.2 以降に導入された新機能である Deferrable Operators(遅延オペレーター) に対応するための Triggererプロセス を起動するサービスです。Deferrable Operator は、非同期で待機可能なタスク(例:センサー系処理)を リソース消費を抑えたまま待機 できる仕組みで、その処理の管理役がこの triggerer です。
airflow-triggerer:
<<: *airflow-common
command: triggerer
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type TriggererJob --hostname "$${HOSTNAME}"']
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfullyairflow-init
初期化用サービスです。
airflow-init:
<<: *airflow-common
entrypoint: /bin/bash
command:
- -c
- |
if [[ -z "${AIRFLOW_UID}" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: AIRFLOW_UID not set!\e[0m"
echo "If you are on Linux, you SHOULD follow the instructions below to set "
echo "AIRFLOW_UID environment variable, otherwise files will be owned by root."
echo "For other operating systems you can get rid of the warning with manually created .env file:"
echo " See: https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#setting-the-right-airflow-user"
echo
export AIRFLOW_UID=$$(id -u)
fi
one_meg=1048576
mem_available=$$(($$(getconf _PHYS_PAGES) * $$(getconf PAGE_SIZE) / one_meg))
cpus_available=$$(grep -cE 'cpu[0-9]+' /proc/stat)
disk_available=$$(df / | tail -1 | awk '{print $$4}')
warning_resources="false"
if (( mem_available < 4000 )) ; then
echo
echo -e "\033[1;33mWARNING!!!: Not enough memory available for Docker.\e[0m"
echo "At least 4GB of memory required. You have $$(numfmt --to iec $$((mem_available * one_meg)))"
echo
warning_resources="true"
fi
if (( cpus_available < 2 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough CPUS available for Docker.\e[0m"
echo "At least 2 CPUs recommended. You have $${cpus_available}"
echo
warning_resources="true"
fi
if (( disk_available < one_meg * 10 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough Disk space available for Docker.\e[0m"
echo "At least 10 GBs recommended. You have $$(numfmt --to iec $$((disk_available * 1024 )))"
echo
warning_resources="true"
fi
if [[ $${warning_resources} == "true" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: You have not enough resources to run Airflow (see above)!\e[0m"
echo "Please follow the instructions to increase amount of resources available:"
echo " https://airflow.apache.org/docs/apache-airflow/stable/howto/docker-compose/index.html#before-you-begin"
echo
fi
echo
echo "Creating missing opt dirs if missing:"
echo
mkdir -v -p /opt/airflow/{logs,dags,plugins,config}
echo
echo "Airflow version:"
/entrypoint airflow version
echo
echo "Files in shared volumes:"
echo
ls -la /opt/airflow/{logs,dags,plugins,config}
echo
echo "Running airflow config list to create default config file if missing."
echo
/entrypoint airflow config list >/dev/null
echo
echo "Files in shared volumes:"
echo
ls -la /opt/airflow/{logs,dags,plugins,config}
echo
echo "Change ownership of files in /opt/airflow to ${AIRFLOW_UID}:0"
echo
chown -R "${AIRFLOW_UID}:0" /opt/airflow/
echo
echo "Change ownership of files in shared volumes to ${AIRFLOW_UID}:0"
echo
chown -v -R "${AIRFLOW_UID}:0" /opt/airflow/{logs,dags,plugins,config}
echo
echo "Files in shared volumes:"
echo
ls -la /opt/airflow/{logs,dags,plugins,config}
environment:
<<: *airflow-common-env
_AIRFLOW_DB_MIGRATE: 'true'
_AIRFLOW_WWW_USER_CREATE: 'true'
_AIRFLOW_WWW_USER_USERNAME: ${_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${_AIRFLOW_WWW_USER_PASSWORD:-airflow}
_PIP_ADDITIONAL_REQUIREMENTS: ''
user: "0:0"postgres
airflowで利用するデータベースサービスです。
postgres:
image: postgres:16
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 10s
retries: 5
start_period: 5s
restart: alwaysredis
Airflow 自体は CeleryExecutor を使っているときに、Redis(またはRabbitMQ)をメッセージブローカーとして使用します。
CeleryExecutorにおけるBrokerとしてのRedis
• Airflow Scheduler や Web UI から送られてくるジョブ情報(TaskInstance)を、Redis 経由で各 Worker に配信する役目
• メッセージキューとして動作し、「このタスクを実行してください」という命令を Redis に一旦貯めて、Worker がそれを取りにいくイメージ
Redis を使う理由
• Celery + Redis の組み合わせにより、タスクの並列実行が可能となる。
• タスクの 分散処理(スケールアウト) に強い。
• RabbitMQ より導入が簡単で軽量、Docker との相性も良い。
redis:
image: redis:7.2-bookworm
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 30s
retries: 50
start_period: 30s
restart: alwaysflower
Flowerとは?
Celery の監視UIツールであり、Airflowが CeleryExecutor を使用している場合に有効です。
以下のような情報をリアルタイムで Web UI から確認できます:
• 各 Worker の状態(起動済み/停止中など)
• 各タスクの実行状況(成功/失敗/保留中)
• タスク実行ログ
• キューの深さ
• リソース負荷状況 など
Celeryとは?
Pythonで書かれた分散タスクキュー/ジョブキューシステムで、非同期処理や並列処理のために広く使われていて以下の特徴があります。
- 複数のワーカーが同時にタスクを処理
- 処理の依頼者(プロデューサー)と、実行者(コンシューマー)を分離
- RedisやRabbitMQをメッセージブローカー(キュー)として利用
- キューにタスクを入れると、Workerがそれを取り出して処理
結局のところ、AirflowにおけるCeleryの役割としては、Airflow で CeleryExecutor を使っている場合、Celeryは以下のように機能するイメージとなります。
- Airflow Scheduler が Redis に「このDAGタスクを実行して」と依頼
- Celery Worker が Redis からタスクを取り出して実行
- 結果を Airflow の DB に記録
つまり、タスクを分散して並列実行したいときの実行基盤として利用します。
flower:
<<: *airflow-common
command: celery flower
profiles:
- flower
ports:
- "5555:5555"
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:5555/"]
interval: 30s
timeout: 10s
retries: 5
start_period: 30s
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully※flowerには、profiles: キーが設定されているので、通常の docker compose up コマンドでは起動されないため、以下のコマンドを別で実行する必要があります。
docker compose --profile flower upAirflowの管理画面にアクセスする
docker compose upでairflowの各種サービスを立ち上げたら、http://localhost:8080 をブラウザで開くと以下のようなログイン画面が表示さるので、Username, Passwordを入力してログインします。
- Username:
airflow - Password:
airflow
ログイン後の管理画面トップページ
Airflowの管理画面の説明については以下公式サイトを参考にしてみてください。
Dagを新規作成してみる
DagのファイルはPythonで記載していきます。
今回は、シンプルにbashを起動するタスクを実行する処理を作成してDagを追加するシンプルな方法を確認していきたいと思います。
事前に押さえておきたいこととしては、Dagの作成方法には2通りのやり方があります。
1つめが、Operatorを使う方法。これは従来の方法でbashを実行する場合は、BashOperatorがあります。
もう1つ目が、Airflow2.0で導入されたTaskFlow APIを使う方法となります。
作成前の予備知識 💡
- ファイルの配置場所
- 今回はAirflow の docker-compose.yaml を使っているので、Dag ファイルはホスト側の
./dagsディレクトリに置きます。 ./dagsディレクトリはdocker volumesでairflowの各コンテナで共有されるようになっています。
- 今回はAirflow の docker-compose.yaml を使っているので、Dag ファイルはホスト側の
TaskFlow APIで Dagを作成してみる
import json
import pendulum
from airflow.sdk import dag, task
@dag(
schedule=None,
start_date=pendulum.datetime(2025, 11, 29, tz="UTC"),
catchup=False,
tags=["example"]
)
def tutorial_taskflow_api():
@task()
def extract():
data_string = '{ "1001": 301.27, "1002": 433.21, "1003": 502.22 }'
order_data_dict = json.loads(data_string)
return order_data_dict
@task(multiple_outputs=True)
def transform(order_data_dict: dict):
total_order_value = 0
for value in (order_data_dict.values()):
total_order_value += value
return { "total_order_value": total_order_value }
@task()
def load(total_order_value: float):
print(f"Total order value is: {total_order_value:.2f}")
order_data = extract()
order_summary = transform(order_data)
load(order_summary["total_order_value"])
tutorial_taskflow_api()
Airflowの管理画面に追加したDagが表示されます。
▷ボタンで実行することができます。
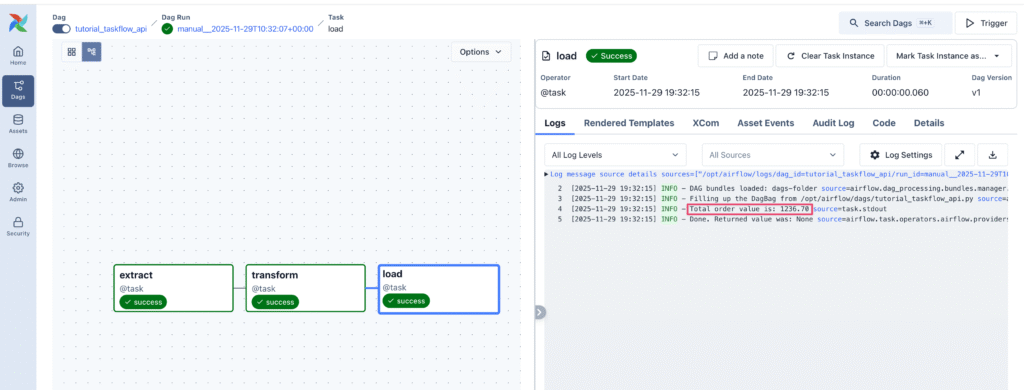
実行した結果`load`タスクでprintしている結果を確認することができます。
Operator(旧方式)でDagを作成したときと比較してみる
以下が同じ処理を旧方式で定義したDagとなります。
import json
import pendulum
from airflow.sdk import DAG
from airflow.providers.standard.operators.python import PythonOperator
def extract():
data_string = '{ "1001": 301.27, "1002": 433.21, "1003": 502.22 }'
return json.loads(data_string)
def transform(ti):
order_data_dict = ti.xcom_pull(task_ids="extract")
total_order_value = sum(order_data_dict.values())
return {"total_order_value": total_order_value}
def load(ti):
total = ti.xcom_pull(task_ids="transform")["total_order_value"]
print(f"Total order value is: {total:.2f}")
with DAG(
dag_id="legacy_etl_pipeline",
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"]
) as dag:
extract_task = PythonOperator(task_id="extract", python_callable=extract)
transform_task = PythonOperator(task_id="transform", python_callable=transform)
load_task = PythonOperator(task_id="load", python_callable=load)
extract_task >> transform_task >> load_task
TaskFlow APIで定義している方がシンプルに定義できるように見えますね。
以上、今回はAirflowの紹介でした。
今後Airflowで調査したいこと
- ユースケース
- ある特定のディレクトリにファイルが配置されたら起動する。
- javaで作成されたバッチをイメージしてjarファイルを起動する。
- 実際の環境どうする?
- クラウドに構築するとしたら?
- クラウドにマネージサービスある?
- データプラットフォームとしての活用方法
- Airflowの機能紹介





コメント